Last summer, I hinted that I was about to switch from the monolithic programme with all its threads to a constellation of separate processes.
The main reason was that the monolithic application needs a restart for any change in the configuration and that a crash/exception on one thread breaks everything.
True, having several separate processes impose to find a way to start them all in the first place and something else to look after them. It also uses quite a bit of memory (because of Python overhead, a tiny process is almost as memory hungry as a small one). Last but not least, the interprocess communication can be problematic.
Enters the Raspberry Pi 2
Fortunately, the Raspberry Pi Foundation released the Raspberry Pi 2 which has now a quad-core CPU, 1GB of memory (and even the Raspberry Pi 3, more recently, but I doubt it would make much difference here). At ~ 3MB of memory per process, there is plenty of available RAM! And also, starting a Python process is now almost immediate compared to the 5-10 seconds needed on the 1-B+ model.
Communication : MQTT
Thinking about it, there is not much need of communication between processes. In the majority of cases, it is all bout sending the data to the display interfaces and to a database (for the sensor part).
Note that so far, I have very little automation (besides a couple of sockets).
Anyway, the ubiquitous MQTT can solve all the communication problems... These days, it seems that there isn't a similar hub project around which isn't using MQTT either at the core or at least for plug-ins communication.
I have already detailed the way I format the topic and the payload of the messages.
Every process is now using a bootstrap library which manages the daemonisation, the MQTT communication, and logs. There are 2 types of messages : the data and metadata (starting, heartbeat, ...).
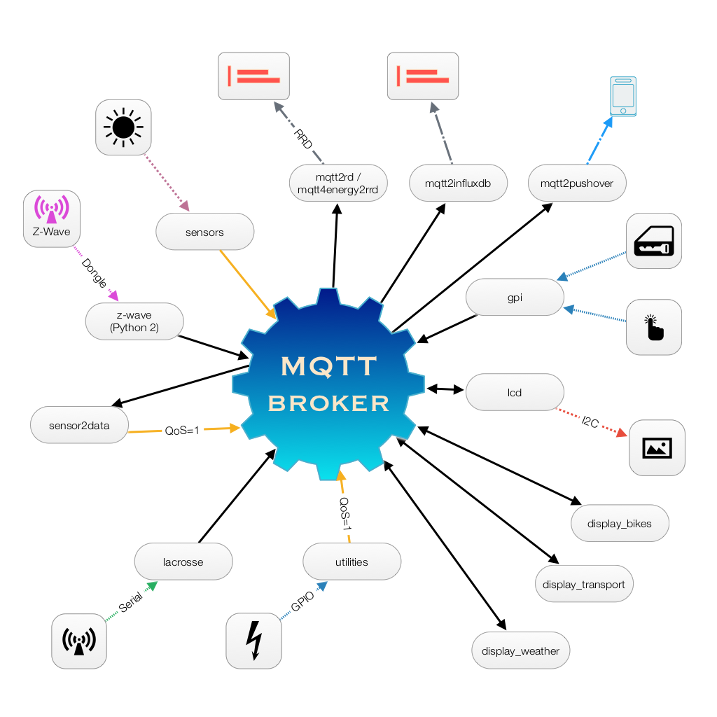
Current state
Currently the model used is the following:
Notes :
All measurements have the MQTT retain option activated to keep the last value available to a reconnecting process
Pushover is a notification system for mobiles (and desktop)
I am currently using 2 storage systems: RRD and a timeseries database (test in progress)
'display_bikes' and 'display_transport' call external webservices and/or doing web scraping of pages. Resulting data is only displayed but never stored.
MQTT used to be the acronym of MQ Telemetry Transport but is now just MQTT is now a OASIS standard for Machine2Machine data sharing. This protocol was invented by Andy Stanford-Clark (IBM) and Arlen Nipper (Arcom, now Cirrus Link) in 1999 and was designed for connections with remote locations where a small code footprint is required or the network bandwidth is limited.
Tutorials
The best explanations I found on the subject come from a series of blog posts by HiveMQ (even if I don't use their product):
There are other posts about security and clients but I think that the ten ones referenced above are a very good introduction.
Basic concepts of MQTT
There is also a IBM redbook called Building Smarter Planet Solutions with MQTT... which is a little bit old and geared towards IBM Websphere MQ product but still interesting and another good presentation of this protocol. Moreover it is free and available in numerous formats.
Extract from the book (chapter 1.2.3):
The MQTT protocol is built upon several basic concepts, all aimed at assuring message delivery while keeping the messages themselves as lightweight as possible.
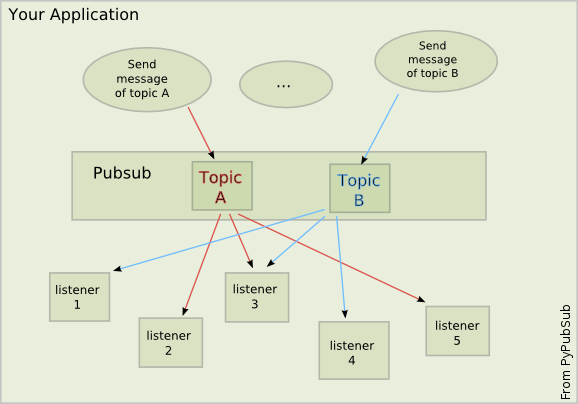
Publish/subscribe
The MQTT protocol is based on the principle of publishing messages and subscribing to topics, which is typically referred to as a publish/subscribe model. Clients can subscribe to topics that pertain to them and thereby receive whatever messages are published to those topics. Alternatively, clients can publish messages to topics, thus making them available to all subscribers to those topics.
Topics and subscriptions
Messages in MQTT are published to topics, which can be thought of as subject areas. Clients, in turn, sign up to receive particular messages by subscribing to a topic. Subscriptions can be explicit, which limits the messages that are received to the specific topic at hand or can use wildcard designators, such as a number sign (#) to receive messages for a variety of related topics.
Quality of service levels
MQTT defines three quality of service (QoS) levels for message delivery, with each level designating a higher level of effort by the server to ensure that the message gets delivered. Higher QoS levels ensure more reliable message delivery but might consume more network bandwidth or subject the message to delays due to issues such as latency.
Retained messages
With MQTT, the server keeps the message even after sending it to all current subscribers. If a new subscription is submitted for the same topic, any retained messages are then sent to the new subscribing client.
Clean sessions and durable connections
When an MQTT client connects to the server, it sets the clean session flag. If the flag is set to true, all of the client's subscriptions are removed when it disconnects from the server. If the flag is set to false, the connection is treated as durable, and the client's subscriptions remain in effect after any disconnection. In this event, subsequent messages that arrive carrying a high QoS designation are stored for delivery after the connection is reestablished. Using the clean session flag is optional.
Wills
When a client connects to a server, it can inform the server that it has a will, or a message, that should be published to a specific topic or topics in the event of an unexpected disconnection. A will is particularly useful in alarm or security settings where system managers must know immediately when a remote sensor has lost contact with the network.
Naming of Topics
If the best practices are rather well defined and mainly:
Through trial and error, I finally settled for the following formats:
group_id/sensor_id/action/action
group_id/sensor_id/data/measurement
group_id/sensor_id/status/heartbeat
For example:
cm/alecto1/data/temperature
cm/alecto1/data/humidity
cm/doorlock/data/status
cm/lcd/status/heartbeat
z-wave/fgk101-1/data/status
z-wave/fgwpe101-1/action/set
Payload
Another problem comes with the payload format. Sometimes the format is part (usually a postfix) of the topic (it is the case with IBM or Xively). It might make sense when the source of data is diverse and unknown but I really don't like it, specially for something all integrated.
At first, I tried to prefix all payloads with a indication of the format. But the result was really different from all the examples and productions I could see around.
Thinking about it, I needed only 2 main "forms" of data:
single value
dictionnary type data: key1="value1" key2="value2" ...
JSON is able to deal with the former case by default. For the single value, it can handle all integer and float values directly. For strings, it is a bit more complicated as string should be between quotes. So the idea now is simply:
First try JSON decoding
If there is an exception, fall back to the raw value
Brokers
There are quite a few brokers around (see here or here) but so far Mosquitto has been perfect on the Raspberry Pi: easy to install, fast and irreproachably stable.
Even the bridge mode between two remote locations worked perfectly the first time.
Nope... Nothing to do with beer nor with underwater exploration!
The Publish-Subscribe pattern is a system where subscribers listen to a particular topic and publishers send messages with that topic. Nothing is send directly from publishers to subscribers. This give a great degree of flexibility.
Application
Why I am talking about this? Simply because if the monolithic application works perfectly. Any change in configuration and/or programme impose a restart (the same way a crash/exception on one thread would break everything).
This is the reason why I am on the path of breaking up all threads into separate processes. Obsviously there is a bit of overhead but I rely on shared libraries to aleviate the waste of memory.
One of the major issues is that all parts now need to communicate between them as they can't share variables any more.
Redis
My first prototypes were using Redis, for storage of value and because it implements a pubsub set of functions. It is a minimalist implementation (no QoS, no bells and whistles) but worked very well.
MQTT
Yet, the most common pub-sub protocol these days seems something called MQTT (used to be an acronym) which is now a OASIS standard for Machine2Machine data sharing. My first thought was that it might be a little bit overkill for interprocess communication but it certainly opens a whole new world.
There are loads of cloud based MQTT brokers (if needed) and you find MQTT libraries for Arduino, etc...